
YOLOv3深入学习
鉴于yolov3对于目标识别界的重大开创性,跳过1、2两个版本直接学习yolov3,同时也作为后续版本的基石入门。
主要原理
1. YOLOv3的核心思想
YOLOv3(You Only Look Once version 3)是一种单阶段目标检测算法,其核心思想是将目标检测问题转化为一个回归问题。与传统的两阶段检测方法(如R-CNN系列)不同,YOLOv3通过单次前向传播直接预测目标的边界框和类别概率,从而实现高效的目标检测。
YOLOv3的主要特点包括:
- 单次前向传播:输入图像经过一次网络前向传播即可得到检测结果。
- 多尺度预测:通过不同尺度的特征图检测不同大小的目标。
- 锚点机制:使用预定义的锚点(anchors)来辅助预测边界框。
2. YOLOv3的网络结构
YOLOv3的网络结构可以分为三个部分:Backbone(骨干网络)、Neck(特征融合部分)**和**Head(检测头)。
2.1 Backbone:Darknet-53
YOLOv3的骨干网络是Darknet-53,它是一个包含53个卷积层的深度卷积神经网络。Darknet-53借鉴了ResNet的思想,使用了残差连接(Residual Connections)来缓解深层网络的梯度消失问题。
Darknet-53的主要特点:
- 使用1x1和3x3卷积层提取特征。
- 使用残差块(Residual Block)来构建深层网络。
- 输出三个不同尺度的特征图(13x13、26x26、52x52),用于多尺度预测。
2.2 Neck:特征金字塔网络(FPN)
YOLOv3通过特征金字塔网络(Feature Pyramid Network, FPN)实现多尺度特征融合。FPN将深层特征图(包含语义信息)与浅层特征图(包含细节信息)进行融合,从而增强网络对不同尺度目标的检测能力。
FPN的工作流程:
- 从深层特征图开始,逐步上采样并与浅层特征图融合。
- 最终生成三个不同尺度的特征图(13x13、26x26、52x52),分别用于检测大、中、小目标。
2.3 Head:检测头
检测头是YOLOv3的输出部分,负责预测边界框和类别概率。每个尺度的特征图都会预测固定数量的边界框(通常是3个),每个边界框包含以下信息:
- 边界框的中心坐标(x, y)。
- 边界框的宽度和高度(w, h)。
- 目标存在的置信度(confidence)。
- 类别概率(class probabilities)。
3. 多尺度预测
YOLOv3在三个不同尺度的特征图上进行预测:
- 13x13特征图:用于检测大目标。
- 26x26特征图:用于检测中等目标。
- 52x52特征图:用于检测小目标。
每个尺度的特征图会被划分为若干网格(grid cell),每个网格负责预测固定数量的边界框。例如,13x13特征图会被划分为13x13个网格,每个网格预测3个边界框。
4. 锚点机制
YOLOv3使用锚点(anchors)来辅助预测边界框。锚点是一组预定义的边界框尺寸,用于帮助网络更好地预测不同大小和形状的目标。
锚点的作用:
- 每个尺度的特征图使用不同的锚点尺寸。例如,13x13特征图使用较大的锚点,52x52特征图使用较小的锚点。
- 网络预测的边界框是基于锚点的偏移量,而不是直接预测边界框的绝对坐标。
5. 边界框的编码与解码
YOLOv3通过编码和解码的方式将预测的边界框与真实边界框进行匹配。
5.1 编码(Encoding)
在训练时,需要将真实的边界框(ground truth)编码为网络输出的格式。
假设我们有一个真实的边界框$ (x, y, w, h) $,对应的锚点为$ (p_w, p_h) $,则编码后的边界框为:
- $ tx = (x - cx) / stride $
- $ ty = (y - cy) / stride $
- $ tw = log(w / p_w) $
- $ th = log(h / p_h) $
其中,$ (cx, cy) $是当前网格的左上角坐标,$ (tx, ty) $是中心偏移量,$ (tw, th) $是缩放比例,$ stride $是特征图的步长。
5.2 解码(Decoding)
在推理时,需要将网络输出的边界框解码为实际的坐标。假设网络输出为$ (tx, ty, tw, th) $,对应的锚点为$ (p_w, p_h) $,则解码后的边界框为:
- $ x = (sigmoid(tx) + cx) * stride $
- $ y = (sigmoid(ty) + cy) * stride $
- $ w = exp(tw) * p_w $
- $ h = exp(th) * p_h $
6. 损失函数
YOLOv3的损失函数由三部分组成:
- 定位损失(Localization Loss):计算预测边界框与真实边界框之间的误差,通常使用均方误差(MSE)。
- 置信度损失(Confidence Loss):计算预测的置信度与真实值之间的误差,通常使用二元交叉熵(Binary Cross-Entropy)。
- 分类损失(Classification Loss):计算预测的类别概率与真实类别之间的误差,通常使用交叉熵(Cross-Entropy)。
7. 训练与推理
7.1 训练
在训练时,YOLOv3通过以下步骤进行优化:
- 输入图像经过网络前向传播,得到三个尺度的预测结果。
- 将预测结果与真实标签进行匹配,计算损失。
- 使用反向传播更新网络参数。
7.2 推理
在推理时,YOLOv3通过以下步骤生成检测结果:
- 输入图像经过网络前向传播,得到三个尺度的预测结果。
- 对预测的边界框进行解码,得到实际的坐标。
- 使用非极大值抑制(NMS)去除重叠的边界框,得到最终的检测结果。
细节实现
1. 网络输出的结构
YOLOv3的网络输出是三个尺度的特征图(13x13、26x26、52x52),每个尺度的特征图会预测固定数量的边界框(通常是3个)。每个边界框的输出包含以下信息:
- 边界框的中心坐标偏移量(tx, ty):相对于当前网格的偏移量。
- 边界框的宽度和高度缩放量(tw, th):相对于锚点的缩放量。
- 目标存在的置信度(confidence):表示当前边界框包含目标的概率。
- 类别概率(class probabilities):表示目标属于每个类别的概率。
假设每个尺度预测3个边界框,类别数为C,则每个尺度的输出维度为:
- 13x13尺度的输出维度:
13 x 13 x 3 x (5 + C) - 26x26尺度的输出维度:
26 x 26 x 3 x (5 + C) - 52x52尺度的输出维度:
52 x 52 x 3 x (5 + C)
其中,5表示边界框的4个坐标值(tx, ty, tw, th)和1个置信度,C表示类别数。
2. 后处理计算
后处理计算的目的是将网络的原始输出转换为实际的边界框坐标和类别信息。具体步骤如下:
2.1 解码边界框坐标
网络的输出是边界框的偏移量和缩放量,需要通过解码将其转换为实际的边界框坐标。
假设网络的输出为$ (tx, ty, tw, th) $,对应的锚点为$ (a_w, a_h) $,当前网格的左上角坐标为$ (cx, cy) $,特征图的步长为$ stride $,则解码后的边界框坐标为:
- 中心坐标:
- $ x = (sigmoid(tx) + cx) * stride $
- $ y = (sigmoid(ty) + cy) * stride $
- 宽度和高度:
- $ w = exp(tw) * p_w $
- $ h = exp(th) * p_h $
其中,$ sigmoid $函数用于将偏移量限制在0到1之间,确保边界框的中心位于当前网格内。
2.2 计算置信度和类别概率
网络的输出还包括置信度和类别概率,需要通过以下步骤进行处理:
- 置信度:直接使用$ sigmoid $函数将输出值转换为概率值,表示当前边界框包含目标的概率。
- 类别概率:对每个类别的输出值应用$ sigmoid $函数,得到每个类别的概率值。
2.3 过滤低置信度的边界框
为了减少计算量,通常会过滤掉置信度低于某个阈值(如0.5)的边界框。只有置信度高于阈值的边界框才会进入下一步处理。
2.4 非极大值抑制(NMS)
非极大值抑制(Non-Maximum Suppression, NMS)用于去除重叠的边界框,保留最优的检测结果。NMS的具体步骤如下:
- 对所有边界框按置信度从高到低排序。
- 选择置信度最高的边界框,将其加入最终结果列表。
- 计算该边界框与其余边界框的交并比(IoU)。
- 删除IoU高于某个阈值(如0.5)的边界框。
- 重复步骤2-4,直到所有边界框都被处理。
3. 置信度的计算
置信度(confidence)是网络输出的一个重要部分,表示当前边界框包含目标的概率。置信度的计算步骤如下:
- 网络输出:网络输出的置信度是一个标量值(通常记为$ t_conf $),范围是任意的(未经过激活函数处理)。
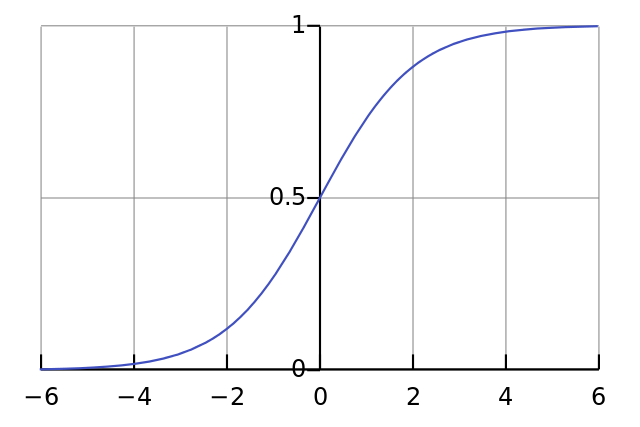
- Sigmoid激活:为了将置信度转换为概率值,需要对$ t_conf $应用Sigmoid函数:
$ \text{confidence} = \sigma(t_conf) = \frac{1}{1 + e^{-t_conf}} $
这样,置信度的值被限制在0到1之间。 - 置信度的意义:置信度表示当前边界框内是否存在目标。如果置信度接近1,说明边界框内很可能存在目标;如果接近0,则说明边界框内很可能没有目标。
3.1 类别概率的计算
类别概率(class probabilities)表示目标属于每个类别的概率。
- 网络输出:网络输出的类别概率是一个长度为$ C $的向量($ C $为类别数),记为$ t_class $。每个值表示对应类别的得分(未经过激活函数处理)。
- Sigmoid激活:对$ t_class $中的每个值应用$ Sigmoid $函数,将其转换为概率值:
$ \text{class_prob}_i = \sigma(t_class_i) = \frac{1}{1 + e^{-t_class_i}} $
这样,每个类别的概率值被限制在0到1之间。 - 类别概率的意义:$ class_prob_i $表示目标属于第$ i $个类别的概率。YOLOv3使用$ Sigmoid $函数而不是$ Softmax $函数,因此每个类别的概率是独立的,可以同时预测多个类别(适用于多标签分类任务)。
3.2 过滤低置信度的边界框
在得到置信度和类别概率后,通常需要过滤掉低置信度的边界框,以减少计算量并提高检测结果的可靠性。具体步骤如下:
- 设置置信度阈值:通常设置一个置信度阈值(如0.5),只有置信度高于该阈值的边界框才会被保留。
- 过滤边界框:遍历所有边界框,保留置信度高于阈值的边界框,丢弃低于阈值的边界框。
3.3 非极大值抑制(NMS)
非极大值抑制(Non-Maximum Suppression, NMS)是目标检测中常用的后处理步骤,用于去除重叠的边界框,保留最优的检测结果。NMS的具体步骤如下:
- 按置信度排序:将所有边界框按置信度从高到低排序。
- 选择最高置信度的边界框:从排序后的列表中选择置信度最高的边界框,将其加入最终结果列表。
- 计算交并比(IoU):计算该边界框与其余所有边界框的交并比(Intersection over Union, IoU)。IoU的计算公式为:
$ \text{IoU} = \frac{\text{Area of Intersection}}{\text{Area of Union}} $
其中,Area of Intersection是两个边界框的交集面积,Area of Union是两个边界框的并集面积。 - 去除重叠边界框:删除与当前边界框IoU高于某个阈值(如0.5)的边界框。
- 重复步骤2-4:重复上述过程,直到所有边界框都被处理。
3. 具体示例
假设我们有一个13x13尺度的输出,类别数为80,锚点为(10, 13), (16, 30), (33, 23),特征图的步长为32。
3.1 网络输出
网络的输出维度为13 x 13 x 3 x 85,其中85 = 5 + 80(5表示边界框的4个坐标值和1个置信度,80表示类别数)。
3.2 解码边界框
对于每个网格和每个锚点,解码边界框的步骤如下:
- 提取$ (tx, ty, tw, th) $和置信度、类别概率。
- 使用$ Sigmoid $函数计算中心坐标偏移量:
- $ x = (\sigma(tx) + cx) \times 32 $
- $ y = (\sigma(ty) + cy) \times 32 $
- 使用指数函数计算宽度和高度:
- $ w = \exp(tw) \times a_w $
- $ h = \exp(th) \times a_h $
- 将边界框坐标转换为$ (x_min, y_min, x_max, y_max) $格式:
- $ x_{\text{min}} = x - w / 2 $
- $ y_{\text{min}} = y - h / 2 $
- $ x_{\text{max}} = x + w / 2 $
- $ y_{\text{max}} = y + h / 2 $
3.3 置信度和类别概率的计算
- 对置信度$ t_conf $应用$ Sigmoid $函数:
$ \text{confidence} = \sigma(t_conf) $ - 对类别概率$ t_class $应用$ Sigmoid $函数:
$ \text{class_prob}_i = \sigma(t_class_i) $
3.4 过滤和NMS
- 过滤掉置信度低于0.5的边界框。
- 对剩余的边界框按置信度排序。
- 使用NMS去除重叠的边界框,保留最优的检测结果。
网络结构
1. 网络架构:Darknet-53
YOLOv3的骨干网络是Darknet-53,这是一个53层的卷积神经网络(CNN),借鉴了ResNet的残差结构,但设计更为轻量化和高效。
1.1 Darknet-53的结构
- 输入:YOLOv3的输入图像尺寸通常为416x416(或其他尺寸,如608x608)。
- 卷积层:Darknet-53主要由卷积层、批量归一化(Batch Normalization)和Leaky ReLU激活函数组成。
- 卷积层:使用3x3和1x1卷积核,3x3卷积用于提取特征,1x1卷积用于调整通道数。
- 批量归一化:加速训练并提高模型稳定性。
- Leaky ReLU:激活函数,公式为 $ f(x) = \max(x, 0.1x) $,避免梯度消失。
- 残差块(Residual Block):Darknet-53的核心组件是残差块,每个残差块包含两个3x3卷积层和一个跳跃连接(Shortcut Connection)。
- 跳跃连接将输入直接加到输出上,缓解梯度消失问题,使网络能够训练得更深。
- Darknet-53共有23个残差块。
1.2 Darknet-53的特点
- 深度:53层网络,比YOLOv2的Darknet-19更深,但比ResNet-152更轻量。
- 效率:Darknet-53在ImageNet分类任务上达到了与ResNet-152相当的精度,但速度更快。
- 多尺度特征提取:Darknet-53通过不同层提取不同尺度的特征,为后续的多尺度预测提供支持。
2. 多尺度预测
YOLOv3在三个不同尺度的特征图上进行目标检测,分别对应13x13、26x26和52x52的特征图。这种多尺度设计使其能够检测不同大小的目标。
2.1 特征金字塔网络(FPN)
YOLOv3借鉴了特征金字塔网络(Feature Pyramid Network, FPN)的思想,通过上采样和特征融合实现多尺度预测。
- 上采样(Upsampling):将低分辨率的特征图通过插值方法(如双线性插值)放大到高分辨率。
- 特征融合:将上采样后的特征图与来自浅层的特征图进行拼接(Concatenation),结合低级特征(细节信息)和高级特征(语义信息)。
- 例如,13x13的特征图通过上采样得到26x26的特征图,然后与Darknet-53中间层的26x26特征图拼接。
2.2 三个尺度的预测
- 13x13特征图:用于检测大目标。
- 26x26特征图:用于检测中等目标。
- 52x52特征图:用于检测小目标。
每个尺度的特征图都会输出预测结果,包括边界框坐标、置信度和类别概率。
3. 锚框(Anchor Boxes)机制
YOLOv3使用锚框(Anchor Boxes)来预测目标的边界框。锚框是预定义的边界框,用于捕捉不同形状和尺寸的目标。
3.1 锚框的选择
- K-means聚类:YOLOv3使用K-means聚类算法从训练数据集中自动学习锚框的尺寸。
- 对训练集中所有目标的边界框进行聚类,得到9个聚类中心(即9个锚框)。
- 这些锚框被分配到三个尺度上,每个尺度分配3个锚框。
- 锚框的尺寸:不同尺度的锚框尺寸不同,例如:
- 13x13尺度的锚框较大,适合检测大目标。
- 52x52尺度的锚框较小,适合检测小目标。
3.2 锚框的预测
- 每个网格单元(Grid Cell)预测3个边界框,每个边界框对应一个锚框。
- 每个边界框预测以下内容:
- 边界框坐标(x, y, w, h):x和y是中心点坐标,w和h是宽度和高度。
- 置信度(Confidence):表示边界框内是否包含目标,以及预测框的准确性。
- 类别概率(Class Probabilities):表示目标属于每个类别的概率。
4. 损失函数
以下是YOLOv3中三个损失计算函数的详细公式和解释:
1. 坐标损失(Coordinate Loss)
坐标损失用于衡量预测的边界框坐标(中心点 (x, y) 和宽高 (w, h))与真实边界框坐标之间的差异。YOLOv3使用均方误差(MSE)来计算坐标损失。
公式:
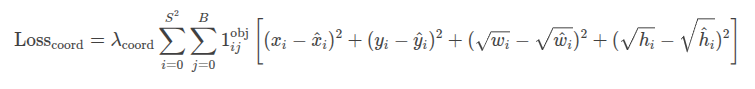
参数说明:
- $ S^2 $:网格单元的数量(例如,13x13、26x26、52x52)。
- $ B $:每个网格单元预测的边界框数量(YOLOv3中 ( B = 3 ))。
- $ \mathbb{1}_{ij}^{\text{obj}} $:指示函数,表示第 ( i ) 个网格单元的第 ( j ) 个边界框是否负责检测目标(如果是则为1,否则为0)。
- $ x_i, y_i $:预测的边界框中心点坐标。
- $ \hat{x}_i, \hat{y}_i $:真实的边界框中心点坐标。
- $ w_i, h_i $:预测的边界框宽度和高度。
- $ \hat{w}_i, \hat{h}_i $:真实的边界框宽度和高度。
- $ \lambda_{\text{coord}} $:坐标损失的权重(通常设置为5)。
2. 置信度损失(Confidence Loss)
置信度损失用于衡量预测的置信度(即边界框内是否包含目标)与真实值之间的差异。YOLOv3使用二分类交叉熵损失来计算置信度损失。
公式:
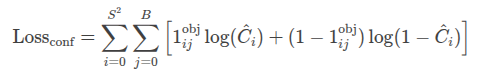
参数说明:
- $ \hat{C}_i $:预测的置信度(即边界框内包含目标的概率)。
- $ \mathbb{1}_{ij}^{\text{obj}} $:指示函数,表示第 ( i ) 个网格单元的第 ( j ) 个边界框是否负责检测目标(如果是则为1,否则为0)。
- 对于负样本(不包含目标的边界框),置信度损失仅计算 $ \log(1 - \hat{C}_i) $。
3. 类别损失(Class Loss)
类别损失用于衡量预测的类别概率与真实类别之间的差异。YOLOv3使用多分类交叉熵损失来计算类别损失。
公式:
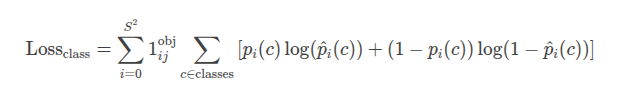
参数说明:
- $ p_i(c) $:真实的类别概率(如果是类别$ c $则为1,否则为0)。
- $ \hat{p}_i(c) $:预测的类别概率(通过$ Sigmoid $函数输出)。
- $ \mathbb{1}_{ij}^{\text{obj}} $:指示函数,表示第 $ i $个网格单元的第$ j $个边界框是否负责检测目标(如果是则为1,否则为0)。
- $ c $:类别索引, $ \text{classes} $是所有类别的集合。
4. 总损失函数
YOLOv3的总损失函数是上述三个损失函数的加权和: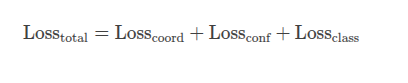
参数说明:
- 总损失函数是坐标损失、置信度损失和类别损失的总和。
- 每个损失函数的权重可以通过超参数调整(例如,坐标损失的权重 $ \lambda_{\text{coord}} $ 通常设置为5)。
5. 训练与推理
5.1 训练
- 数据增强:使用随机裁剪、翻转、颜色抖动等技术增强数据。
- 损失优化:通过反向传播优化损失函数,更新网络参数。
- 预训练:Darknet-53通常在ImageNet数据集上进行预训练,然后在目标检测任务上进行微调。
5.2 推理
- 输入图像:将图像调整为固定尺寸(如416x416)并输入网络。
- 预测输出:网络输出三个尺度的预测结果。
- 非极大值抑制(NMS):去除重叠的边界框,保留置信度最高的预测框。
代码阅读(汉化)
1 | # Ultralytics YOLOv3 🚀, AGPL-3.0 license |
"""
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = (
Path(opt.save_dir),
opt.epochs,
opt.batch_size,
opt.weights,
opt.single_cls,
opt.evolve,
opt.data,
opt.cfg,
opt.resume,
opt.noval,
opt.nosave,
opt.workers,
opt.freeze,
)
callbacks.run("on_pretrain_routine_start")
# 目录
w = save_dir / "weights" # 权重目录
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # 创建目录
last, best = w / "last.pt", w / "best.pt"
# 超参数
if isinstance(hyp, str):
with open(hyp, errors="ignore") as f:
hyp = yaml.safe_load(f) # 加载超参数字典
LOGGER.info(colorstr("超参数: ") + ", ".join(f"{k}={v}" for k, v in hyp.items()))
opt.hyp = hyp.copy() # 保存超参数到检查点
# 保存运行设置
if not evolve:
yaml_save(save_dir / "hyp.yaml", hyp)
yaml_save(save_dir / "opt.yaml", vars(opt))
# 日志记录器
data_dict = None
if RANK in {-1, 0}:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # 日志记录器实例
# 注册动作
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# 处理自定义数据集工件链接
data_dict = loggers.remote_dataset
if resume: # 如果从远程工件恢复运行
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# 配置
plots = not evolve and not opt.noplots # 创建图表
cuda = device.type != "cpu"
init_seeds(opt.seed + 1 + RANK, deterministic=True)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # 检查是否为None
train_path, val_path = data_dict["train"], data_dict["val"]
nc = 1 if single_cls else int(data_dict["nc"]) # 类别数量
names = {0: "item"} if single_cls and len(data_dict["names"]) != 1 else data_dict["names"] # 类别名称
is_coco = isinstance(val_path, str) and val_path.endswith("coco/val2017.txt") # COCO数据集
# 模型
check_suffix(weights, ".pt") # 检查权重
pretrained = weights.endswith(".pt")
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # 如果本地没有找到则下载
ckpt = torch.load(weights, map_location="cpu") # 将检查点加载到CPU以避免CUDA内存泄漏
model = Model(cfg or ckpt["model"].yaml, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # 创建模型
exclude = ["anchor"] if (cfg or hyp.get("anchors")) and not resume else [] # 排除键
csd = ckpt["model"].float().state_dict() # 检查点状态字典为FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # 交集
model.load_state_dict(csd, strict=False) # 加载
LOGGER.info(f"从 {weights} 转移了 {len(csd)}/{len(model.state_dict())} 项") # 报告
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get("anchors")).to(device) # 创建模型
amp = check_amp(model) # 检查AMP
# 冻结
freeze = [f"model.{x}." for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # 冻结的层
for k, v in model.named_parameters():
v.requires_grad = True # 训练所有层
# v.register_hook(lambda x: torch.nan_to_num(x)) # NaN转为0(注释掉以避免训练结果不稳定)
if any(x in k for x in freeze):
LOGGER.info(f"冻结 {k}")
v.requires_grad = False
# 图像大小
gs = max(int(model.stride.max()), 32) # 网格大小(最大步幅)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # 验证imgsz是gs的倍数
# 批量大小
if RANK == -1 and batch_size == -1: # 仅限单GPU,估计最佳批量大小
batch_size = check_train_batch_size(model, imgsz, amp)
loggers.on_params_update({"batch_size": batch_size})
# 优化器
nbs = 64 # 名义批量大小
accumulate = max(round(nbs / batch_size), 1) # 在优化前累积损失
hyp["weight_decay"] *= batch_size * accumulate / nbs # 缩放权重衰减
optimizer = smart_optimizer(model, opt.optimizer, hyp["lr0"], hyp["momentum"], hyp["weight_decay"])
# 学习率调度器
if opt.cos_lr:
lf = one_cycle(1, hyp["lrf"], epochs) # 余弦 1->hyp['lrf']
else:
def lf(x):
"""线性学习率调度器函数,根据epoch比例计算衰减。"""
return (1 - x / epochs) * (1.0 - hyp["lrf"]) + hyp["lrf"] # 线性
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in {-1, 0} else None
# 恢复
best_fitness, start_epoch = 0.0, 0
if pretrained:
if resume:
best_fitness, start_epoch, epochs = smart_resume(ckpt, optimizer, ema, weights, epochs, resume)
del ckpt, csd
# DP模式
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning(
"警告 ⚠️ 不推荐使用DP模式,建议使用torch.distributed.run以获得最佳DDP多GPU结果。\n"
"请参阅多GPU教程:https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training 以开始使用。"
)
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info("使用 SyncBatchNorm()")
# 训练数据加载器
train_loader, dataset = create_dataloader(
train_path,
imgsz,
batch_size // WORLD_SIZE,
gs,
single_cls,
hyp=hyp,
augment=True,
cache=None if opt.cache == "val" else opt.cache,
rect=opt.rect,
rank=LOCAL_RANK,
workers=workers,
image_weights=opt.image_weights,
quad=opt.quad,
prefix=colorstr("训练: "),
shuffle=True,
seed=opt.seed,
)
labels = np.concatenate(dataset.labels, 0)
mlc = int(labels[:, 0].max()) # 最大标签类别
assert mlc < nc, f"标签类别 {mlc} 超过了 {data} 中的 nc={nc}。可能的类别标签是 0-{nc - 1}"
# 进程0
if RANK in {-1, 0}:
val_loader = create_dataloader(
val_path,
imgsz,
batch_size // WORLD_SIZE * 2,
gs,
single_cls,
hyp=hyp,
cache=None if noval else opt.cache,
rect=True,
rank=-1,
workers=workers * 2,
pad=0.5,
prefix=colorstr("验证: "),
)[0]
if not resume:
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp["anchor_t"], imgsz=imgsz) # 运行AutoAnchor
model.half().float() # 预降低锚点精度
callbacks.run("on_pretrain_routine_end", labels, names)
# DDP模式
if cuda and RANK != -1:
model = smart_DDP(model)
# 模型属性
nl = de_parallel(model).model[-1].nl # 检测层数量(用于缩放超参数)
hyp["box"] *= 3 / nl # 按层缩放
hyp["cls"] *= nc / 80 * 3 / nl # 按类别和层缩放
hyp["obj"] *= (imgsz / 640) ** 2 * 3 / nl # 按图像大小和层缩放
hyp["label_smoothing"] = opt.label_smoothing
model.nc = nc # 将类别数量附加到模型
model.hyp = hyp # 将超参数附加到模型
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # 将类别权重附加到模型
model.names = names
# 开始训练
t0 = time.time()
nb = len(train_loader) # 批次数量
nw = max(round(hyp["warmup_epochs"] * nb), 100) # 预热迭代次数,最大(3个epoch,100次迭代)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # 将预热限制在训练的一半以下
last_opt_step = -1
maps = np.zeros(nc) # 每个类别的mAP
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # 不要移动
scaler = torch.cuda.amp.GradScaler(enabled=amp)
stopper, stop = EarlyStopping(patience=opt.patience), False
compute_loss = ComputeLoss(model) # 初始化损失类
callbacks.run("on_train_start")
LOGGER.info(
f'图像大小 {imgsz} 训练, {imgsz} 验证\n'
f'使用 {train_loader.num_workers * WORLD_SIZE} 个数据加载器工作进程\n'
f"记录结果到 {colorstr('bold', save_dir)}\n"
f'开始训练 {epochs} 个epoch...'
)
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
callbacks.run("on_train_epoch_start")
model.train()
# 更新图像权重(可选,仅限单GPU)
if opt.image_weights:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # 类别权重
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # 图像权重
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # 随机加权索引
# 更新马赛克边框(可选)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # 高度,宽度边框
mloss = torch.zeros(3, device=device) # 平均损失
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(("\n" + "%11s" * 7) % ("Epoch", "GPU_mem", "box_loss", "obj_loss", "cls_loss", "Instances", "Size"))
if RANK in {-1, 0}:
pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT) # 进度条
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
callbacks.run("on_train_batch_start")
ni = i + nb * epoch # 自训练开始以来的集成批次数量
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8转为float32,0-255转为0.0-1.0
# 预热
if ni <= nw:
xi = [0, nw] # x插值
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou损失比率(obj_loss = 1.0或iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr从0.1下降到lr0,其他lr从0.0上升到lr0
x["lr"] = np.interp(ni, xi, [hyp["warmup_bias_lr"] if j == 0 else 0.0, x["initial_lr"] * lf(epoch)])
if "momentum" in x:
x["momentum"] = np.interp(ni, xi, [hyp["warmup_momentum"], hyp["momentum"]])
# 多尺度
if opt.multi_scale:
sz = random.randrange(int(imgsz * 0.5), int(imgsz * 1.5) + gs) // gs * gs # 大小
sf = sz / max(imgs.shape[2:]) # 缩放因子
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # 新形状(拉伸到gs倍数)
imgs = nn.functional.interpolate(imgs, size=ns, mode="bilinear", align_corners=False)
# 前向传播
with torch.cuda.amp.autocast(amp):
pred = model(imgs) # 前向传播
loss, loss_items = compute_loss(pred, targets.to(device)) # 损失按批量大小缩放
if RANK != -1:
loss *= WORLD_SIZE # 在DDP模式下梯度在设备间平均
if opt.quad:
loss *= 4.0
# 反向传播
scaler.scale(loss).backward()
# 优化 - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= accumulate:
scaler.unscale_(optimizer) # 取消梯度缩放
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # 梯度裁剪
scaler.step(optimizer) # 优化器步骤
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# 日志
if RANK in {-1, 0}:
mloss = (mloss * i + loss_items) / (i + 1) # 更新平均损失
mem = f"{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G" # (GB)
pbar.set_description(
("%11s" * 2 + "%11.4g" * 5)
% (f"{epoch}/{epochs - 1}", mem, *mloss, targets.shape[0], imgs.shape[-1])
)
callbacks.run("on_train_batch_end", model, ni, imgs, targets, paths, list(mloss))
if callbacks.stop_training:
return
# 结束批次 ------------------------------------------------------------------------------------------------
# 学习率调度器
lr = [x["lr"] for x in optimizer.param_groups] # 用于日志记录器
scheduler.step()
if RANK in {-1, 0}:
# mAP
callbacks.run("on_train_epoch_end", epoch=epoch)
ema.update_attr(model, include=["yaml", "nc", "hyp", "names", "stride", "class_weights"])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # 计算mAP
results, maps, _ = validate.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
half=amp,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss,
)
# 更新最佳mAP
fi = fitness(np.array(results).reshape(1, -1)) # [P, R, mAP@.5, mAP@.5-.95]的加权组合
stop = stopper(epoch=epoch, fitness=fi) # 早停检查
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run("on_fit_epoch_end", log_vals, epoch, best_fitness, fi)
# 保存模型
if (not nosave) or (final_epoch and not evolve): # 如果保存
ckpt = {
"epoch": epoch,
"best_fitness": best_fitness,
"model": deepcopy(de_parallel(model)).half(),
"ema": deepcopy(ema.ema).half(),
"updates": ema.updates,
"optimizer": optimizer.state_dict(),
"opt": vars(opt),
"git": GIT_INFO, # {remote, branch, commit} 如果是git仓库
"date": datetime.now().isoformat(),
}
# 保存最后、最佳并删除
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if opt.save_period > 0 and epoch % opt.save_period == 0:
torch.save(ckpt, w / f"epoch{epoch}.pt")
del ckpt
callbacks.run("on_model_save", last, epoch, final_epoch, best_fitness, fi)
# 早停
if RANK != -1: # 如果是DDP训练
broadcast_list = [stop if RANK == 0 else None]
dist.broadcast_object_list(broadcast_list, 0) # 将'stop'广播到所有rank
if RANK != 0:
stop = broadcast_list[0]
if stop:
break # 必须中断所有DDP rank
# 结束epoch ----------------------------------------------------------------------------------------------------
# 结束训练 -----------------------------------------------------------------------------------------------------
if RANK in {-1, 0}:
LOGGER.info(f"\n{epoch - start_epoch + 1} 个epoch在 {(time.time() - t0) / 3600:.3f} 小时内完成。")
for f in last, best:
if f.exists():
strip_optimizer(f) # 去除优化器
if f is best:
LOGGER.info(f"\n验证 {f}...")
results, _, _ = validate.run(
data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # 最佳pycocotools在iou 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=plots,
callbacks=callbacks,
compute_loss=compute_loss,
) # 使用图表验证最佳模型
if is_coco:
callbacks.run("on_fit_epoch_end", list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run("on_train_end", last, best, epoch, results)
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
“””
解析命令行参数以配置YOLO模型的训练。
参数:
known (bool): 仅解析已知参数的标志,默认为False。
返回:
(argparse.Namespace): 解析后的命令行参数。
示例:
1
2
options = parse_opt()
print(options.weights)
注意:
* 默认权重路径为 'yolov3-tiny.pt'。
* 设置 `known` 为True以仅解析已知参数,适用于部分参数解析。
参考:
* 模型: https://github.com/ultralytics/yolov5/tree/master/models
* 数据集: https://github.com/ultralytics/yolov5/tree/master/data
* 训练教程: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
"""
parser = argparse.ArgumentParser()
parser.add_argument("--weights", type=str, default=ROOT / "yolov3-tiny.pt", help="初始权重路径")
parser.add_argument("--cfg", type=str, default="", help="模型yaml路径")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="数据集yaml路径")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="超参数路径")
parser.add_argument("--epochs", type=int, default=100, help="总训练epoch数")
parser.add_argument("--batch-size", type=int, default=16, help="所有GPU的总批量大小,-1表示自动批量")
parser.add_argument("--imgsz", "--img", "--img-size", type=int, default=640, help="训练、验证图像大小(像素)")
parser.add_argument("--rect", action="store_true", help="矩形训练")
parser.add_argument("--resume", nargs="?", const=True, default=False, help="恢复最近的训练")
parser.add_argument("--nosave", action="store_true", help="仅保存最终检查点")
parser.add_argument("--noval", action="store_true", help="仅在最终epoch验证")
parser.add_argument("--noautoanchor", action="store_true", help="禁用AutoAnchor")
parser.add_argument("--noplots", action="store_true", help="不保存任何图表文件")
parser.add_argument("--evolve", type=int, nargs="?", const=300, help="超参数进化x代")
parser.add_argument("--bucket", type=str, default="", help="gsutil存储桶")
parser.add_argument("--cache", type=str, nargs="?", const="ram", help="图像缓存 ram/disk")
parser.add_argument("--image-weights", action="store_true", help="使用加权图像选择进行训练")
parser.add_argument("--device", default="", help="cuda设备,例如 0 或 0,1,2,3 或 cpu")
parser.add_argument("--multi-scale", action="store_true", help="图像大小变化 +/- 50%%")
parser.add_argument("--single-cls", action="store_true", help="将多类数据训练为单类")
parser.add_argument("--optimizer", type=str, choices=["SGD", "Adam", "AdamW"], default="SGD", help="优化器")
parser.add_argument("--sync-bn", action="store_true", help="使用SyncBatchNorm,仅在DDP模式下可用")
parser.add_argument("--workers", type=int, default=8, help="最大数据加载器工作进程数(DDP模式下每rank)")
parser.add_argument("--project", default=ROOT / "runs/train", help="保存到project/name")
parser.add_argument("--name", default="exp", help="保存到project/name")
parser.add_argument("--exist-ok", action="store_true", help="允许现有project/name,不递增")
parser.add_argument("--quad", action="store_true", help="四倍数据加载器")
parser.add_argument("--cos-lr", action="store_true", help="余弦学习率调度器")
parser.add_argument("--label-smoothing", type=float, default=0.0, help="标签平滑epsilon")
parser.add_argument("--patience", type=int, default=100, help="早停耐心(无改进的epoch数)")
parser.add_argument("--freeze", nargs="+", type=int, default=[0], help="冻结层:backbone=10, first3=0 1 2")
parser.add_argument("--save-period", type=int, default=-1, help="每x个epoch保存检查点(如果小于1则禁用)")
parser.add_argument("--seed", type=int, default=0, help="全局训练种子")
parser.add_argument("--local_rank", type=int, default=-1, help="自动DDP多GPU参数,不要修改")
# 日志记录器参数
parser.add_argument("--entity", default=None, help="实体")
parser.add_argument("--upload_dataset", nargs="?", const=True, default=False, help='上传数据,"val"选项')
parser.add_argument("--bbox_interval", type=int, default=-1, help="设置边界框图像记录间隔")
parser.add_argument("--artifact_alias", type=str, default="latest", help="数据集工件的版本")
return parser.parse_known_args()[0] if known else parser.parse_args()
def main(opt, callbacks=Callbacks()):
“””
主训练/进化脚本,处理模型检查、DDP设置、训练和超参数进化。
参数:
opt (argparse.Namespace): 解析后的命令行选项。
callbacks (Callbacks, 可选): 处理训练事件的回调对象。默认为Callbacks()。
返回:
None
异常:
AssertionError: 如果某些约束被违反(例如,当特定选项与DDP训练不兼容时)。
注意:
- 有关使用DDP进行多GPU训练的教程:https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training
示例:
单GPU训练:
1
2
$ python train.py --data coco128.yaml --weights yolov5s.pt --img 640 # 从预训练模型开始训练(推荐)
$ python train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # 从零开始训练
多GPU DDP训练:
1
2
$ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 train.py --data coco128.yaml \
--weights yolov5s.pt --img 640 --device 0,1,2,3
模型: https://github.com/ultralytics/yolov5/tree/master/models
数据集: https://github.com/ultralytics/yolov5/tree/master/data
教程: https://docs.ultralytics.com/yolov5/tutorials/train_custom_data
"""
if RANK in {-1, 0}:
print_args(vars(opt))
check_git_status()
check_requirements(ROOT / "requirements.txt")
# 恢复(从指定或最近的last.pt)
if opt.resume and not check_comet_resume(opt) and not opt.evolve:
last = Path(check_file(opt.resume) if isinstance(opt.resume, str) else get_latest_run())
opt_yaml = last.parent.parent / "opt.yaml" # 训练选项yaml
opt_data = opt.data # 原始数据集
if opt_yaml.is_file():
with open(opt_yaml, errors="ignore") as f:
d = yaml.safe_load(f)
else:
d = torch.load(last, map_location="cpu")["opt"]
opt = argparse.Namespace(**d) # 替换
opt.cfg, opt.weights, opt.resume = "", str(last), True # 恢复
if is_url(opt_data):
opt.data = check_file(opt_data) # 避免HUB恢复认证超时
else:
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = (
check_file(opt.data),
check_yaml(opt.cfg),
check_yaml(opt.hyp),
str(opt.weights),
str(opt.project),
) # 检查
assert len(opt.cfg) or len(opt.weights), "必须指定 --cfg 或 --weights"
if opt.evolve:
if opt.project == str(ROOT / "runs/train"): # 如果默认项目名称,重命名为runs/evolve
opt.project = str(ROOT / "runs/evolve")
opt.exist_ok, opt.resume = opt.resume, False # 将resume传递给exist_ok并禁用resume
if opt.name == "cfg":
opt.name = Path(opt.cfg).stem # 使用model.yaml作为名称
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# DDP模式
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
msg = "与YOLOv3多GPU DDP训练不兼容"
assert not opt.image_weights, f"--image-weights {msg}"
assert not opt.evolve, f"--evolve {msg}"
assert opt.batch_size != -1, f"自动批量 --batch-size -1 {msg}, 请传递有效的 --batch-size"
assert opt.batch_size % WORLD_SIZE == 0, f"--batch-size {opt.batch_size} 必须是 WORLD_SIZE 的倍数"
assert torch.cuda.device_count() > LOCAL_RANK, "DDP命令的CUDA设备不足"
torch.cuda.set_device(LOCAL_RANK)
device = torch.device("cuda", LOCAL_RANK)
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
# 训练
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
# 超参数进化(可选)
else:
# 超参数进化元数据(突变比例0-1,下限,上限)
meta = {
"lr0": (1, 1e-5, 1e-1), # 初始学习率(SGD=1E-2, Adam=1E-3)
"lrf": (1, 0.01, 1.0), # 最终OneCycleLR学习率(lr0 * lrf)
"momentum": (0.3, 0.6, 0.98), # SGD动量/Adam beta1
"weight_decay": (1, 0.0, 0.001), # 优化器权重衰减
"warmup_epochs": (1, 0.0, 5.0), # 预热epoch数(可以是小数)
"warmup_momentum": (1, 0.0, 0.95), # 预热初始动量
"warmup_bias_lr": (1, 0.0, 0.2), # 预热初始偏差学习率
"box": (1, 0.02, 0.2), # 框损失增益
"cls": (1, 0.2, 4.0), # 类别损失增益
"cls_pw": (1, 0.5, 2.0), # 类别BCELoss正样本权重
"obj": (1, 0.2, 4.0), # 目标损失增益(按像素缩放)
"obj_pw": (1, 0.5, 2.0), # 目标BCELoss正样本权重
"iou_t": (0, 0.1, 0.7), # IoU训练阈值
"anchor_t": (1, 2.0, 8.0), # 锚点倍数阈值
"anchors": (2, 2.0, 10.0), # 每个输出网格的锚点数量(0表示忽略)
"fl_gamma": (0, 0.0, 2.0), # 焦点损失gamma(efficientDet默认gamma=1.5)
"hsv_h": (1, 0.0, 0.1), # 图像HSV-Hue增强(比例)
"hsv_s": (1, 0.0, 0.9), # 图像HSV-Saturation增强(比例)
"hsv_v": (1, 0.0, 0.9), # 图像HSV-Value增强(比例)
"degrees": (1, 0.0, 45.0), # 图像旋转(+/- 度)
"translate": (1, 0.0, 0.9), # 图像平移(+/- 比例)
"scale": (1, 0.0, 0.9), # 图像缩放(+/- 增益)
"shear": (1, 0.0, 10.0), # 图像剪切(+/- 度)
"perspective": (0, 0.0, 0.001), # 图像透视(+/- 比例),范围0-0.001
"flipud": (1, 0.0, 1.0), # 图像上下翻转(概率)
"fliplr": (0, 0.0, 1.0), # 图像左右翻转(概率)
"mosaic": (1, 0.0, 1.0), # 图像马赛克(概率)
"mixup": (1, 0.0, 1.0), # 图像混合(概率)
"copy_paste": (1, 0.0, 1.0),
} # 分段复制粘贴(概率)
with open(opt.hyp, errors="ignore") as f:
hyp = yaml.safe_load(f) # 加载超参数字典
if "anchors" not in hyp: # 如果hyp.yaml中注释了anchors
hyp["anchors"] = 3
if opt.noautoanchor:
del hyp["anchors"], meta["anchors"]
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # 仅在最终epoch验证/保存
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # 可进化的索引
evolve_yaml, evolve_csv = save_dir / "hyp_evolve.yaml", save_dir / "evolve.csv"
if opt.bucket:
# 如果存在则下载evolve.csv
subprocess.run(
[
"gsutil",
"cp",
f"gs://{opt.bucket}/evolve.csv",
str(evolve_csv),
]
)
for _ in range(opt.evolve): # 进化代数
if evolve_csv.exists(): # 如果evolve.csv存在:选择最佳超参数并突变
# 选择父代
parent = "single" # 父代选择方法:'single' 或 'weighted'
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=",", skiprows=1)
n = min(5, len(x)) # 考虑的前n个结果
x = x[np.argsort(-fitness(x))][:n] # 前n个突变
w = fitness(x) - fitness(x).min() + 1e-6 # 权重(总和 > 0)
if parent == "single" or len(x) == 1:
# x = x[random.randint(0, n - 1)] # 随机选择
x = x[random.choices(range(n), weights=w)[0]] # 加权选择
elif parent == "weighted":
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # 加权组合
# 突变
mp, s = 0.8, 0.2 # 突变概率,sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # 增益 0-1
ng = len(meta)
v = np.ones(ng)
while all(v == 1): # 突变直到发生变化(防止重复)
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # 突变
# 限制在范围内
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # 下限
hyp[k] = min(hyp[k], v[2]) # 上限
hyp[k] = round(hyp[k], 5) # 有效数字
# 训练突变
results = train(hyp.copy(), opt, device, callbacks)
callbacks = Callbacks()
# 写入突变结果
keys = (
"metrics/precision",
"metrics/recall",
"metrics/mAP_0.5",
"metrics/mAP_0.5:0.95",
"val/box_loss",
"val/obj_loss",
"val/cls_loss",
)
print_mutation(keys, results, hyp.copy(), save_dir, opt.bucket)
# 绘制结果
plot_evolve(evolve_csv)
LOGGER.info(
f'超参数进化完成 {opt.evolve} 代\n'
f"结果保存到 {colorstr('bold', save_dir)}\n"
f'使用示例: $ python train.py --hyp {evolve_yaml}'
)
def run(**kwargs):
“””
使用指定配置运行YOLOv3模型的训练过程。
参数:
data (str): 数据集YAML文件的路径。
weights (str): 预训练权重文件的路径或 '' 表示从零开始训练。
cfg (str): 模型配置文件的路径。
hyp (str): 超参数YAML文件的路径。
epochs (int): 总训练epoch数。
batch_size (int): 所有GPU的总批量大小。
imgsz (int): 训练和验证的图像大小(像素)。
rect (bool): 使用矩形训练以更好地保留宽高比。
resume (bool | str): 如果为True,则恢复最近的训练,如果为字符串,则从特定检查点恢复训练。
nosave (bool): 仅保存最终检查点,不保存中间检查点。
noval (bool): 仅在最终epoch验证模型性能。
noautoanchor (bool): 禁用自动锚点生成。
noplots (bool): 不保存任何图表。
evolve (int): 超参数进化的代数。
bucket (str): 用于保存运行工件的Google Cloud Storage存储桶名称。
cache (str | None): 缓存图像以加快训练速度('ram' 或 'disk')。
image_weights (bool): 使用加权图像选择进行训练。
device (str): 用于训练的设备,例如 '0' 表示第一个GPU或 'cpu' 表示CPU。
multi_scale (bool): 使用多尺度训练。
single_cls (bool): 将多类数据集训练为单类。
optimizer (str): 使用的优化器('SGD', 'Adam', 或 'AdamW')。
sync_bn (bool): 使用同步批归一化(仅在DDP模式下可用)。
workers (int): 最大数据加载器工作进程数(DDP模式下每rank)。
project (str): 输出目录的位置。
name (str): 运行的唯一名称。
exist_ok (bool): 允许现有输出目录。
quad (bool): 使用四倍数据加载器。
cos_lr (bool): 使用余弦学习率调度器。
label_smoothing (float): 标签平滑epsilon。
patience (int): 早停耐心(无改进的epoch数)。
freeze (list[int]): 冻结的层列表,例如 [0] 表示仅冻结第一层。
save_period (int): 每 'save_period' 个epoch保存检查点(如果小于1则禁用)。
seed (int): 全局训练种子以确保可重复性。
local_rank (int): 用于自动DDP多GPU参数解析,不要修改。
返回:
None
示例:
1
2
from ultralytics import run
run(data='coco128.yaml', weights='yolov5m.pt', imgsz=320, epochs=100, batch_size=16)
注意:
- 确保数据集YAML文件和初始权重可访问。
- 参考 [Ultralytics YOLOv5 仓库](https://github.com/ultralytics/yolov5) 获取模型和数据配置。
- 使用 [训练教程](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) 进行自定义数据集训练。
"""
opt = parse_opt(True)
for k, v in kwargs.items():
setattr(opt, k, v)
main(opt)
return opt
if name == “main“:
opt = parse_opt()
main(opt)
1 |
|
“””
source = str(source)
save_img = not nosave and not source.endswith(“.txt”) # 保存推理图像
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith((“rtsp://“, “rtmp://“, “http://“, “https://“))
webcam = source.isnumeric() or source.endswith(“.streams”) or (is_url and not is_file)
screenshot = source.lower().startswith(“screen”)
if is_url and is_file:
source = check_file(source) # 下载
# 目录
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # 递增运行
(save_dir / "labels" if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # 创建目录
# 加载模型
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # 检查图像尺寸
# 数据加载器
bs = 1 # 批量大小
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# 运行推理
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # 预热
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 转换为 fp16/32
im /= 255 # 0 - 255 转换为 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # 扩展为批量维度
# 推理
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# 第二阶段分类器 (可选)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# 处理预测结果
for i, det in enumerate(pred): # 每张图像
seen += 1
if webcam: # 批量大小 >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f"{i}: "
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, "frame", 0)
p = Path(p) # 转换为 Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / "labels" / p.stem) + ("" if dataset.mode == "image" else f"_{frame}") # im.txt
s += "{:g}x{:g} ".format(*im.shape[2:]) # 打印字符串
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # 归一化增益 whwh
imc = im0.copy() if save_crop else im0 # 用于保存裁剪
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# 将框从 img_size 缩放到 im0 尺寸
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# 打印结果
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # 每个类别的检测数
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # 添加到字符串
# 写入结果
for *xyxy, conf, cls in reversed(det):
if save_txt: # 写入文件
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # 归一化 xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # 标签格式
with open(f"{txt_path}.txt", "a") as f:
f.write(("%g " * len(line)).rstrip() % line + "\n")
if save_img or save_crop or view_img: # 添加边界框到图像
c = int(cls) # 整数类别
label = None if hide_labels else (names[c] if hide_conf else f"{names[c]} {conf:.2f}")
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / "crops" / names[c] / f"{p.stem}.jpg", BGR=True)
# 流式结果
im0 = annotator.result()
if view_img:
if platform.system() == "Linux" and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # 允许窗口调整大小 (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 毫秒
# 保存结果 (带检测的图像)
if save_img:
if dataset.mode == "image":
cv2.imwrite(save_path, im0)
else: # 'video' 或 'stream'
if vid_path[i] != save_path: # 新视频
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # 释放之前的视频写入器
if vid_cap: # 视频
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # 流
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix(".mp4")) # 强制结果视频为 *.mp4 后缀
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
vid_writer[i].write(im0)
# 打印时间 (仅推理)
LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
# 打印结果
t = tuple(x.t / seen * 1e3 for x in dt) # 每张图像的速度
LOGGER.info(f"Speed: %.1fms 预处理, %.1fms 推理, %.1fms NMS 每张图像 at shape {(1, 3, *imgsz)}" % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} 标签保存到 {save_dir / 'labels'}" if save_txt else ""
LOGGER.info(f"结果保存到 {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights[0]) # 更新模型 (修复 SourceChangeWarning)
def parse_opt():
“””
解析并返回用于运行 YOLOv3 模型检测的命令行选项。
参数:
--weights (list[str]): 模型路径或 Triton URL。默认: ROOT / "yolov3-tiny.pt"。
--source (str): 输入数据源,如文件/目录/URL/通配符/截图/0(网络摄像头)。默认: ROOT / "data/images"。
--data (str): 可选的数据集.yaml 路径。默认: ROOT / "data/coco128.yaml"。
--imgsz (list[int]): 推理尺寸,格式为高度, 宽度。接受多个值。默认: [640]。
--conf-thres (float): 预测的置信度阈值。默认: 0.25。
--iou-thres (float): 非最大抑制 (NMS) 的交并比 (IoU) 阈值。默认: 0.45。
--max-det (int): 每张图像的最大检测数。默认: 1000。
--device (str): CUDA 设备标识符,例如 "0" 或 "0,1,2,3" 或 "cpu"。默认: "" (自动选择)。
--view-img (bool): 显示结果。默认: False。
--save-txt (bool): 将结果保存到 *.txt 文件。默认: False。
--save-conf (bool): 在文本标签中保存置信度分数。默认: False。
--save-crop (bool): 保存裁剪的预测框。默认: False。
--nosave (bool): 不保存带有检测结果的图像/视频。默认: False。
--classes (list[int] | None): 按类别过滤结果,例如 [0, 2, 3]。默认: None。
--agnostic-nms (bool): 执行类别无关的 NMS。默认: False。
--augment (bool): 应用增强推理。默认: False。
--visualize (bool): 可视化特征图。默认: False。
--update (bool): 更新所有模型。默认: False。
--project (str): 保存结果的目录;结果保存到 "project/name"。默认: ROOT / "runs/detect"。
--name (str): 特定运行的名称;结果保存到 "project/name"。默认: "exp"。
--exist-ok (bool): 允许结果保存到现有目录而不递增。默认: False。
--line-thickness (int): 边界框线条的厚度 (像素)。默认: 3。
--hide-labels (bool): 隐藏检测结果中的标签。默认: False。
--hide-conf (bool): 隐藏标签中的置信度分数。默认: False。
--half (bool): 使用 FP16 半精度推理。默认: False。
--dnn (bool): 使用 OpenCV DNN 后端进行 ONNX 推理。默认: False。
--vid-stride (int): 视频输入的帧率步长。默认: 1。
返回:
argparse.Namespace: 解析的命令行参数,用于 YOLOv3 推理配置。
示例:
1
2
options = parse_opt()
run(**vars(options))
"""
parser = argparse.ArgumentParser()
parser.add_argument(
"--weights", nargs="+", type=str, default=ROOT / "yolov3-tiny.pt", help="模型路径或 triton URL"
)
parser.add_argument("--source", type=str, default=ROOT / "data/images", help="文件/目录/URL/通配符/截图/0(网络摄像头)")
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="(可选) 数据集.yaml 路径")
parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[640], help="推理尺寸 h,w")
parser.add_argument("--conf-thres", type=float, default=0.25, help="置信度阈值")
parser.add_argument("--iou-thres", type=float, default=0.45, help="NMS IoU 阈值")
parser.add_argument("--max-det", type=int, default=1000, help="每张图像的最大检测数")
parser.add_argument("--device", default="", help="cuda 设备,例如 0 或 0,1,2,3 或 cpu")
parser.add_argument("--view-img", action="store_true", help="显示结果")
parser.add_argument("--save-txt", action="store_true", help="将结果保存到 *.txt")
parser.add_argument("--save-conf", action="store_true", help="在 --save-txt 标签中保存置信度")
parser.add_argument("--save-crop", action="store_true", help="保存裁剪的预测框")
parser.add_argument("--nosave", action="store_true", help="不保存图像/视频")
parser.add_argument("--classes", nargs="+", type=int, help="按类别过滤:--classes 0 或 --classes 0 2 3")
parser.add_argument("--agnostic-nms", action="store_true", help="类别无关的 NMS")
parser.add_argument("--augment", action="store_true", help="增强推理")
parser.add_argument("--visualize", action="store_true", help="可视化特征")
parser.add_argument("--update", action="store_true", help="更新所有模型")
parser.add_argument("--project", default=ROOT / "runs/detect", help="将结果保存到 project/name")
parser.add_argument("--name", default="exp", help="将结果保存到 project/name")
parser.add_argument("--exist-ok", action="store_true", help="允许现有 project/name 目录而不递增")
parser.add_argument("--line-thickness", default=3, type=int, help="边界框厚度 (像素)")
parser.add_argument("--hide-labels", default=False, action="store_true", help="隐藏标签")
parser.add_argument("--hide-conf", default=False, action="store_true", help="隐藏置信度")
parser.add_argument("--half", action="store_true", help="使用 FP16 半精度推理")
parser.add_argument("--dnn", action="store_true", help="使用 OpenCV DNN 进行 ONNX 推理")
parser.add_argument("--vid-stride", type=int, default=1, help="视频帧率步长")
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # 扩展
print_args(vars(opt))
return opt
def main(opt):
“””
运行 YOLO 模型的入口点;检查需求并使用解析的选项调用 run。
参数:
opt (argparse.Namespace): 解析的命令行选项,包括:
- weights (str | list of str): 模型权重路径或 Triton 服务器 URL。
- source (str): 输入源,可以是文件、目录、URL、通配符、截图或网络摄像头索引。
- data (str): 数据集配置文件路径 (.yaml)。
- imgsz (tuple of int): 推理图像尺寸,格式为 (高度, 宽度)。
- conf_thres (float): 检测的置信度阈值。
- iou_thres (float): 非最大抑制 (NMS) 的交并比 (IoU) 阈值。
- max_det (int): 每张图像的最大检测数。
- device (str): 运行推理的设备;选项为 CUDA 设备 id(s) 或 'cpu'。
- view_img (bool): 显示推理结果的标志。
- save_txt (bool): 将检测结果保存为 .txt 格式。
- save_conf (bool): 在 .txt 标签中保存检测置信度。
- save_crop (bool): 保存裁剪的边界框预测。
- nosave (bool): 不保存带有检测结果的图像/视频。
- classes (list of int): 按类别过滤结果,例如 --class 0 2 3。
- agnostic_nms (bool): 使用类别无关的 NMS。
- augment (bool): 启用增强推理。
- visualize (bool): 可视化特征图。
- update (bool): 在推理过程中更新模型。
- project (str): 保存结果的目录。
- name (str): 结果目录的名称。
- exist_ok (bool): 允许现有 project/name 目录而不递增。
- line_thickness (int): 边界框线条的厚度。
- hide_labels (bool): 在边界框上隐藏类别标签。
- hide_conf (bool): 在边界框上隐藏置信度分数。
- half (bool): 使用 FP16 半精度推理。
- dnn (bool): 使用 OpenCV DNN 后端进行 ONNX 推理。
- vid_stride (int): 视频帧率步长。
返回:
None
示例:
1
2
3
if __name__ == "__main__":
opt = parse_opt()
main(opt)
注意:
将此函数作为使用 YOLO 进行对象检测的入口点,支持多种输入源,如图像、视频、目录、网络摄像头、流媒体等。该函数确保检查所有需求,并通过调用 `run` 函数启动检测过程。
"""
check_requirements(ROOT / "requirements.txt", exclude=("tensorboard", "thop"))
run(**vars(opt))
if name == “main“:
opt = parse_opt()
main(opt)
```
