
神经网络初识
参考资料:
新手入门python实现神经网络,超级简单!_py 神经网络-CSDN博客
Python学习篇30-神经网络_python神经网络-CSDN博客
“反向传播算法”过程及公式推导(超直观好懂的Backpropagation)-CSDN博客
反向传播算法推导过程(看一篇就够了)_神经网络反向传播算法推导-CSDN博客
1.发展历史
神经网络的发展历史可以追溯到20世纪中叶。
- McCulloch和Pitts的神经元模型(1943):
Warren McCulloch和Walter Pitts提出了神经元模型,将神经元抽象为二进制开关,形成了后来神经网络的基础。
- 感知器的提出(1957):
Frank Rosenblatt提出了感知器,这是一种基于神经元模型的学习算法。感知器可以实现简单的二分类任务。
- 早期神经网络的研究(1960s-1970s):
在这一时期,神经网络受到了关注,但受到了硬件和理论上的限制。神经网络的训练和应用遇到了困难。
- 反向传播算法的提出(1986):
- David Rumelhart、Geoffrey Hinton和Ronald Williams提出了反向传播算法,为多层神经网络的训练提供了有效的方法。这一突破重新激发了对神经网络的研究兴趣。
- 计算能力的提升(1990s):
随着计算能力的提高,研究者们开始更深入地研究神经网络的理论和应用。但由于数据集和计算资源的限制,发展相对较慢。
- 深度学习的崛起(2000年后):
- 随着大规模数据集和强大的计算能力的可用性,深度学习(深度神经网络)再次引起了广泛关注。
- 图像分类、语音识别、自然语言处理等领域的成功应用推动了神经网络的发展。
- 卷积神经网络(CNN)和循环神经网络(RNN)的出现:
- 2012年,AlexNet的成功标志着卷积神经网络(CNN)的兴起,对图像处理任务取得了巨大成功。
- 循环神经网络(RNN)在处理序列数据(如自然语言)方面表现出色,为更多领域的应用提供了解决方案。
- 深度学习在各领域的广泛应用:
- 深度学习技术在计算机视觉、自然语言处理、语音识别、医学影像等领域取得了显著的进展,推动了人工智能的发展。
2.主体流程
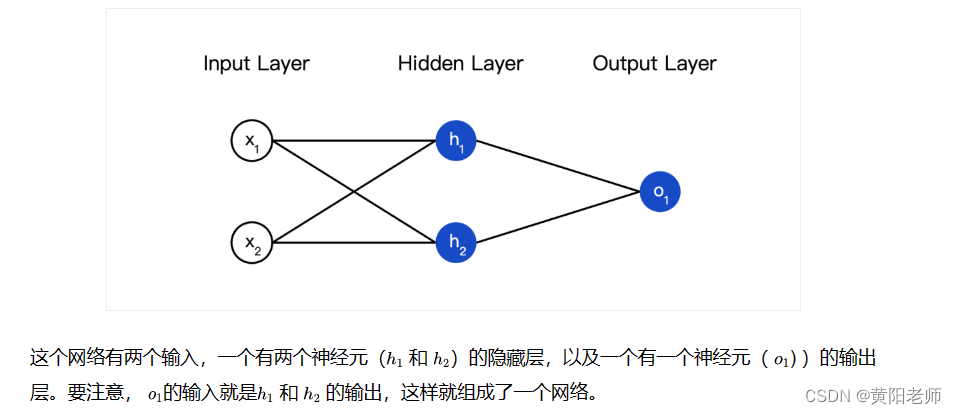
输入层(Input Layer):
- 神经网络的第一层,负责接收输入数据。每个输入节点对应输入数据的一个特征。
权重和偏差(Weights and Biases):
- 每个连接(神经元之间的连接)都有一个权重,用于调整输入的影响力。每个神经元还有一个偏差,用于调整整体激活的阈值。
线性组合(Linear Combination):
- 输入层的每个神经元将其输入与相应的权重相乘,然后将所有乘积相加,再加上偏差。这形成了线性组合。
激活函数(Activation Function):
- 线性组合的结果通常通过激活函数,如Sigmoid、ReLU等,以引入非线性特性。这使得神经网络能够学习非线性关系。这个函数有点像高中学过的神经元阈值(神经网络似乎就是模拟人脑结构),当输入信号或信号组合以某种方式达到一定阈值,才会激活这个节点。
隐藏层(Hidden Layers):
- 在输入层和输出层之间的层称为隐藏层。神经网络的深度取决于隐藏层的数量。每个隐藏层的神经元接收前一层的输出,并重复之前的步骤。
输出层(Output Layer):
- 最后一个隐藏层的输出作为神经网络的最终输出。输出的数量通常取决于任务类型,如二分类问题有一个输出节点,多分类问题有多个输出节点。
损失函数(Loss Function):
- 损失函数度量神经网络输出与真实标签之间的差异。训练过程的目标是最小化损失函数。
优化算法(Optimization Algorithm):
- 优化算法,如梯度下降,用于调整权重和偏差,以降低损失函数。通过计算损失函数关于权重和偏差的梯度,优化算法更新参数。
反向传播(Backpropagation):
- 反向传播算法是训练神经网络的关键步骤。通过计算梯度,反向传播从输出层到输入层反向传播误差,并更新权重和偏差。
训练和预测(Training and Prediction):
- 神经网络通过多次迭代训练数据来学习权重和偏差。在训练后,神经网络可以用于对新数据的预测。
正则化和调参(Regularization and Hyperparameter Tuning):
- 为了提高泛化能力,可以使用正则化技术,并调整超参数(如学习率、隐藏层节点数)。
3.矩阵的应用
学习资料与平台
【官方双语】深度学习之神经网络的结构 Part 1 ver 2.0_哔哩哔哩_bilibili
【官方双语】深度学习之梯度下降法 Part 2 ver 0.9 beta_哔哩哔哩_bilibili
【官方双语】深度学习之反向传播算法 上/下 Part 3 ver 0.9 beta_哔哩哔哩_bilibili
(作为计算机专业小白常常听说线性代数在计算机领域尤其重要,今天才真正理解)。
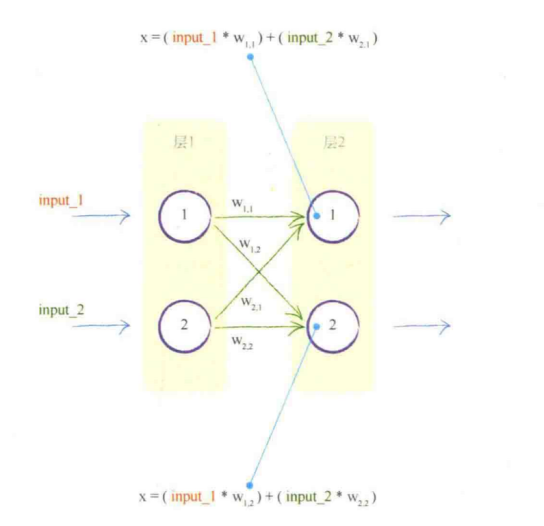
在神经网络的构建中,存在着巨量的参数权重,每一层的数据都代表着运算量进一步飙升。矩阵作为一种数据间关系表达的优良方式(其实就是数表),可以极大程度的简化运算,并能非常简易地表示出结果。下例:
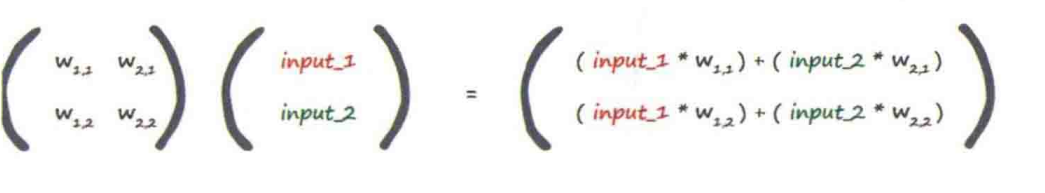
4.梯度下降
梯度:
- 梯度表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(梯度的方向)变化最快,变化率(梯度的模)最大,可理解为导数。
- 梯度上升和梯度下降是优化算法中常用的两种方法,主要目的是通过迭代找到目标函数的最大值和最小值。
例如:
- 想象我们在一座很高的山上,怎么才能以最快的速度下山?我们可以先选择坡度最倾斜的方向走一段距离,然后再重新选择坡度最倾斜的方向,再走一段距离。以此类推,我们就可以以最快的速度到达山底。(梯度的方向,就是我们要选择的方向)
梯度下降法:
梯度下降算法针对的是最小优化问题(即求最小值问题),目的是使目标函数沿最快路径下降到最小值。
通俗的解释,是模拟下山,每次沿着当前位置最陡峭最易下山的方向前进一小步,然后继续沿下一个位置最陡方向前进一小步。这样一步一步走下去,一直走到觉得我们已经到了山脚。
算法作用于损失函数(也称目标函数、代价函数、误差函数),是为了找到使损失函数取最小值的权重(w)和偏置(b)。
梯度下降运行步骤:
- 用随机值初始化权重和偏差
- 把输入传入网络,得到输出值(预测值)
- 计算预测值和真实值(标签值)之间的误差
- 对每一个产生误差的神经元,调整相应的(权重和偏差)值以减小误差
- 重复迭代,直至得到网络权重和偏差的最佳值
批量梯度下降法(BGD):每次迭代计算梯度,使用整个数据集。每次更新都会朝着正确的方向进行,最后能够保证收敛于极值点,凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点,缺陷就是学习时间太长,消耗大量内存。
随机梯度下降法(SGD):每次迭代计算梯度,从整个数据集中随机选取一个数据,所以每次迭代的时间非常快。但收敛时震荡,不稳定,在最优解附近波动,难以判断是否已经收敛。
小批量梯度下降法(MBGD):这个是 BGD 和 SGD 的折中方法, BGD 每次使用整体数据,收敛太慢, SGD 每次只使用一条数据,虽然收敛快但震荡厉害,所以出现了折中的 MBGD,每次使用 n 条数据,如果 n(batch size) 选择的合适,不仅收敛速度比SGD更快、更稳定,而且在最优解附近的震荡也不会很大,甚至得到比 BGD 更好的解。
batch size 的选择,一般取2的幂次时能充分利用矩阵运算操作,因此可以在2的幂次中挑选最优取值。例如16、32、64、128、256等等。
5.反向传播
定义
首先来一个反向传播算法的定义(转自维基百科):反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
首先拿一个简单的三层神经网络来举例,如下: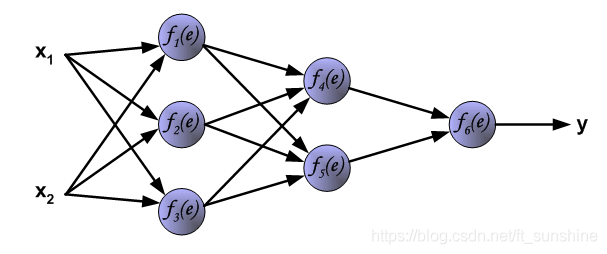
正向传播
每个神经元由两部分组成,第一部分(e)是输入值和权重系数乘积的和,第二部分(f(e))是一个激活函数(非线性函数)的输出, y=f(e)即为某个神经元的输出,如下: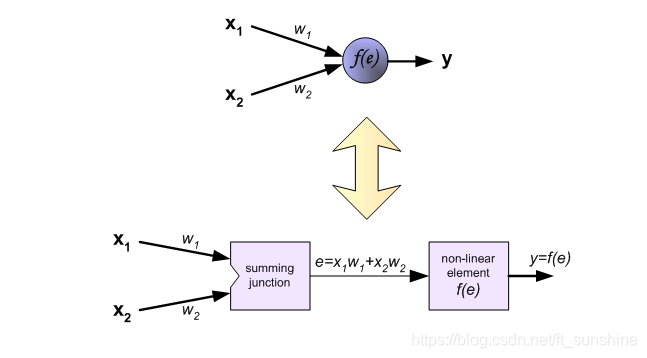
下面是前向传播过程: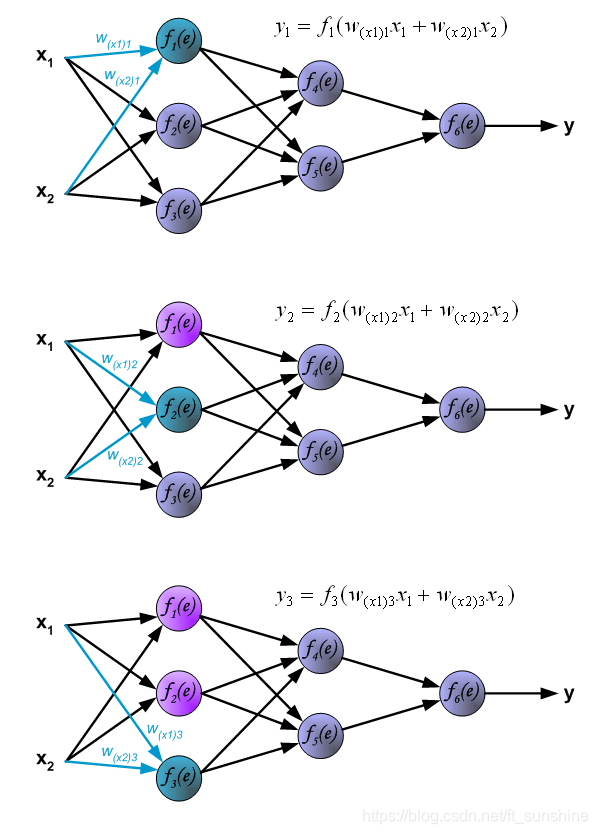
—————-手动分割—————-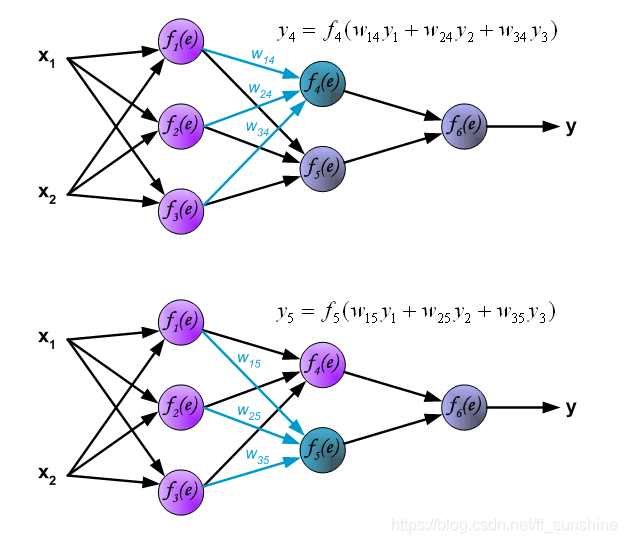
—————-手动分割—————-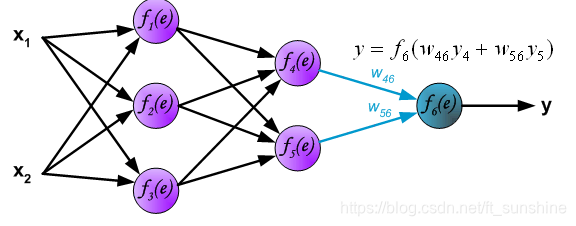
到这里为止,神经网络的前向传播已经完成,最后输出的y就是本次前向传播神经网络计算出来的结果(预测结果),但这个预测结果不一定是正确的,要和真实的标签(z)相比较,计算预测结果和真实标签的误差(δ \deltaδ),如下: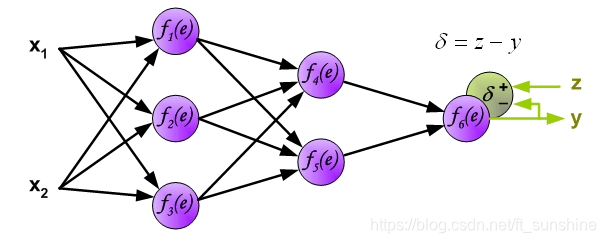
下面开始计算每个神经元的误差(δ \deltaδ):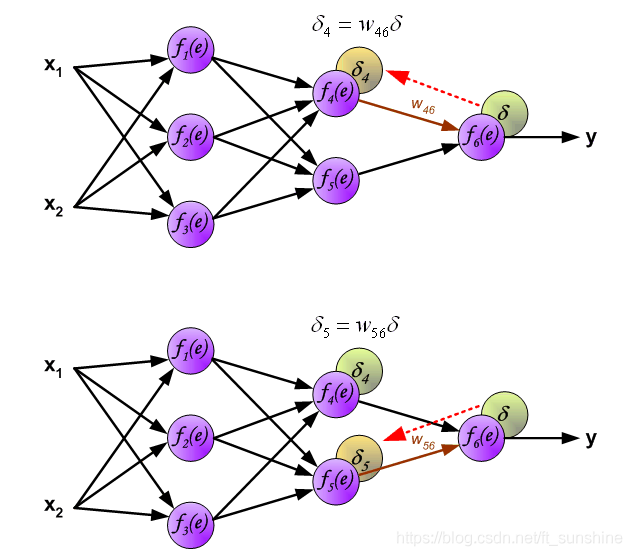
反向传播
下面开始利用反向传播的误差,计算各个神经元(权重)的导数,开始反向传播修改权重。
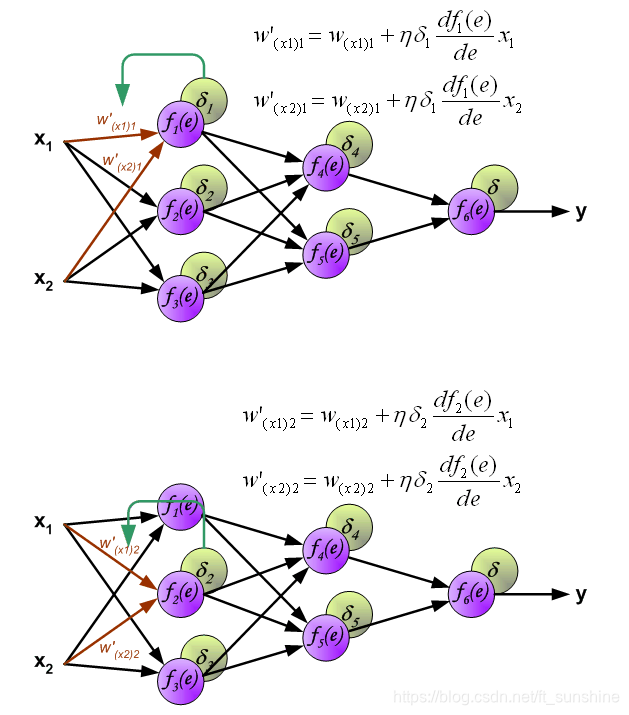
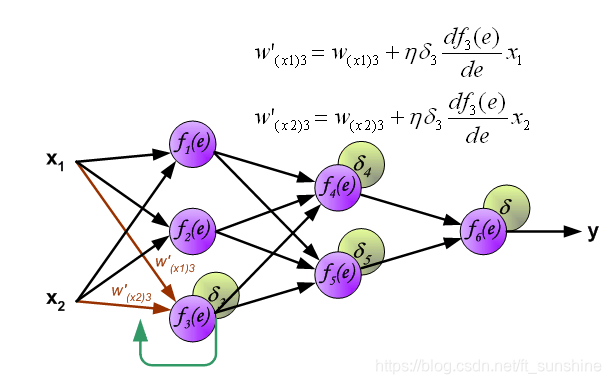
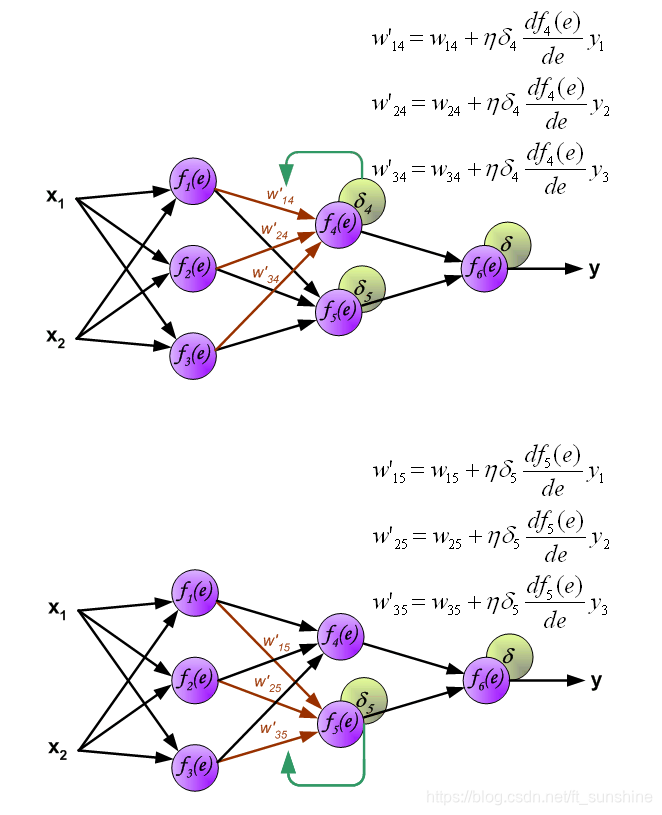
“正向传播”求损失,“反向传播”回传误差。
BP算法,也叫**δ \deltaδ算法**,下面以3层的感知机为例进行举例讲解。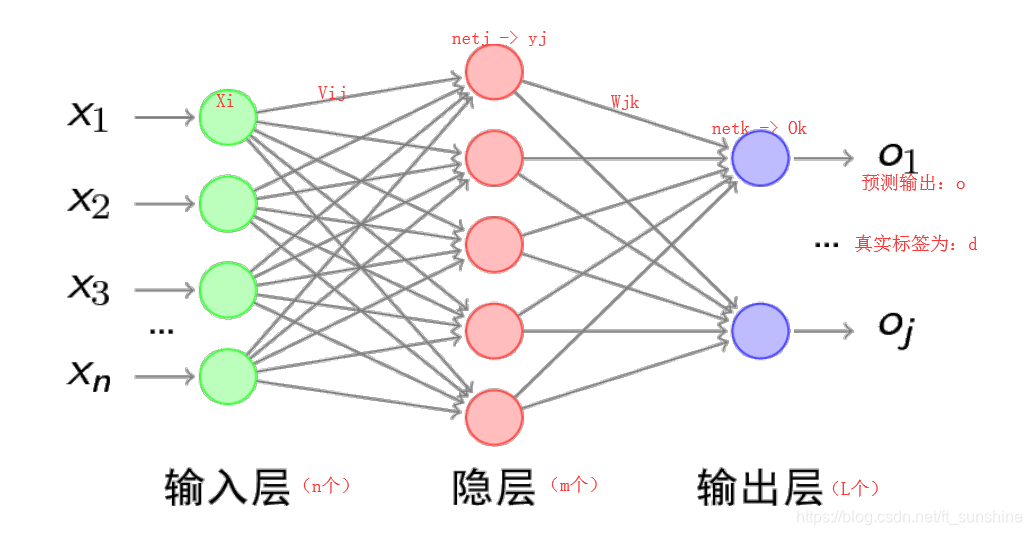
上图的前向传播(网络输出计算)过程如下:(此处为网络的整个误差的计算,误差E计算方法为mse)

上面的计算过程并不难,只要耐心一步步的拆开式子,逐渐分解即可。现在还有两个问题需要解决:
- 误差E有了,怎么调整权重让误差不断减小?
- E是权重w的函数,何如找到使得函数值最小的w。
(其实这些稀奇古怪的公式已经看不懂了)
通俗来讲,反向传播就是根据计算结果的误差修改权重信号,俗称打哪指哪,像极了我强行凑答案的样子。通过这种方法可以优化神经网络的整体权重布局,从而使训练结果更上一层楼(也可能中间层的黑箱子照着无法预测的方向走远但是结果准确率超高)
小结
综上所述感觉神经网络就是人们用计算机模拟人脑神经元链接构建出来的玩意(果然生物结构才是顶级码农的创造)。对于深度学习,神经网络属于机器学习的一部分,更具体地说是深度学习的一种。机器学习是一种让计算机从数据中学习的方法,而深度学习则是机器学习中的一个分支,强调使用深层次的神经网络结构。
对于神经网络是否智能这件事,我也说不好,感觉相对人脑来说这种结构实在是太简单了。(比如说计算机永远无法理解我怎么眼睁睁地看着自己把7x8算成45)。目前神经网络似乎缺少了较高程度的自我学习能力,例如发现个什么定律啥的,(照《终结者》一比还是差着层次),但是chatgpt确实很香,看起来AI方面的发展还是很大的,贾维斯指日可待(乐)。
操作实例
直接上代码吧,内容都写在注释里了
神经网络类:
1 | # -*- coding: utf-8 -*- |
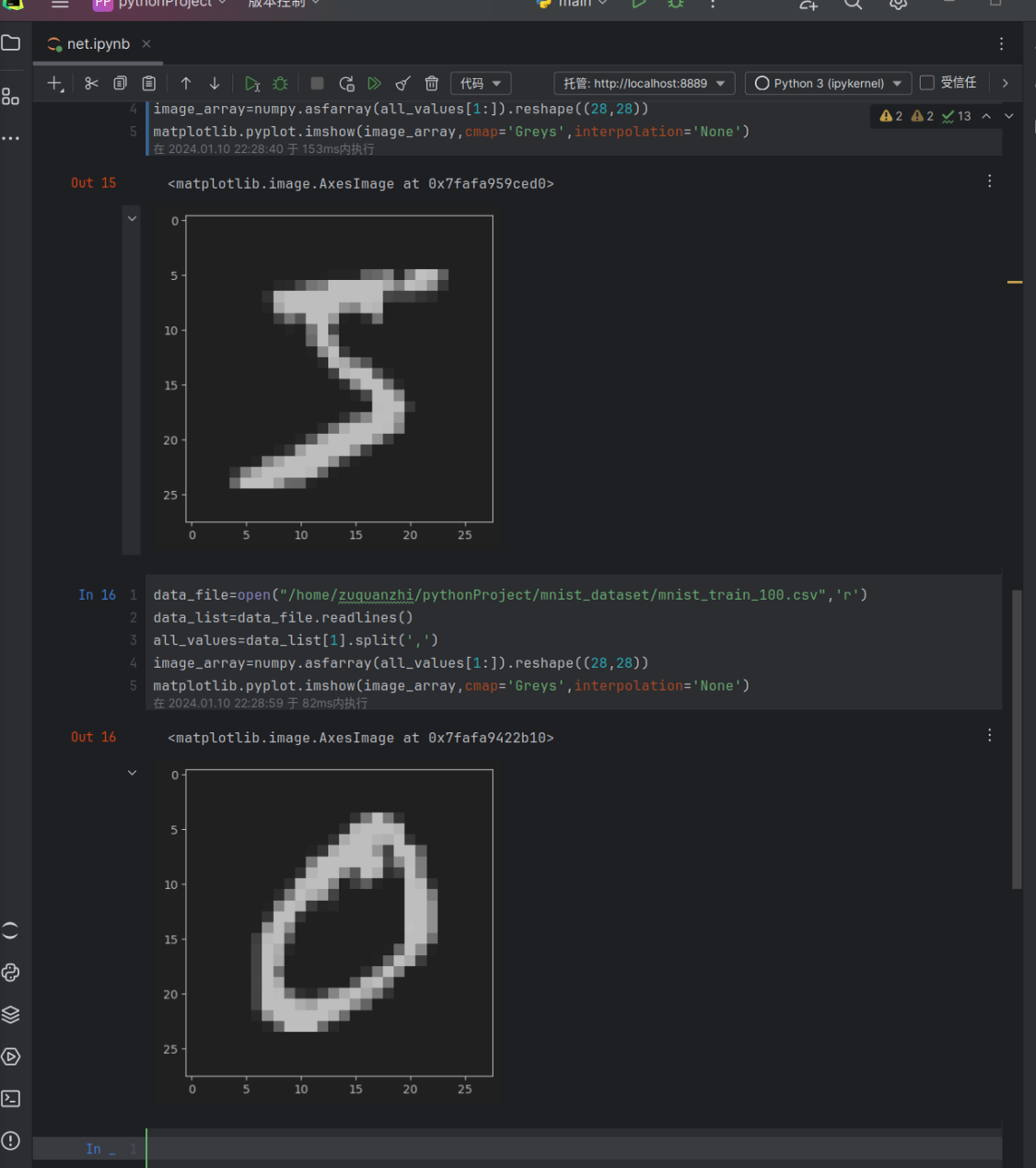
1 | data_file=open("/home/zuquanzhi/pythonProject/mnist_dataset/mnist_train.csv",'r') |
- data_file=…:打开 MNIST 训练数据集文件,并将其内容读取到 data_list 列表中。
- data_list=data_file.readlines():读取文件的所有行,并存储在 data_list 列表中。
- all_values=data_list[0].split(‘,’):将第一行数据按逗号分隔,存储到 all_values 列表中。
- image_array=numpy.asfarray(all_values[1:]).reshape((28,28)):将 all_values 中的像素值转换为浮点数,并重新形状为 28x28 的数组,表示图像的像素矩阵。
- matplotlib.pyplot.imshow(image_array,cmap=’Greys’,interpolation=’None’):使用 Matplotlib 的 imshow 函数将图像以灰度的形式显示在图像窗口中。
这段代码读取 MNIST 数据集中的第一张图像数据,并显示在图像窗口中。
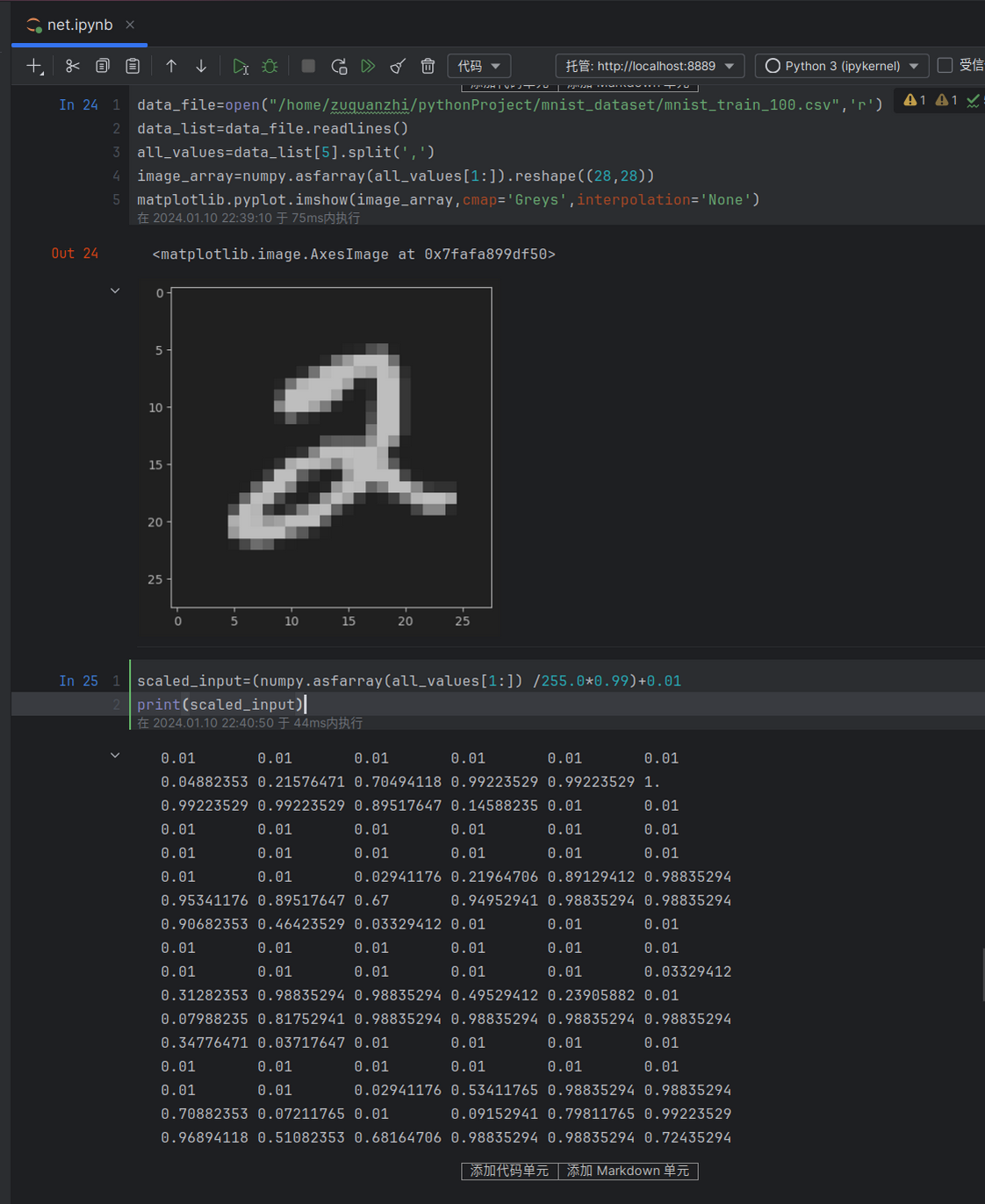
1 | data_file=open("/home/zuquanzhi/pythonProject/mnist_dataset/mnist_train.csv",'r') |
data_list[5] 表示第6行数据,all_values=data_list[5].split(‘,’) 将这一行数据根据逗号分割成一个值的列表。然后,将列表中除第一个值外的其余值转换为浮点数数组,并reshape为28x28的图像矩阵,最后使用matplotlib库将图像显示在灰度色图上。
(其实就是根据数据显示原图)
1 | scaled_input=(numpy.asfarray(all_values[1:]) /255.0*0.99)+0.01 |
这段代码对MNIST数据集中第6行的像素值进行了预处理。首先,numpy.asfarray(all_values[1:]) 将第6行除第一个值外的其余值转换为浮点数数组。然后,通过除以255.0将像素值缩放到0到1之间,接着将数据范围缩放到0.01到1之间,而不是0到1。这是因为在神经网络中,为了避免输入值为0的情况(可能会影响权重的更新),将数据范围设置为稍微偏离0的范围。
最后,通过print(scaled_input) 将缩放后的输入值打印出来,以便查看处理后的数值范围和数据。
这段代码可以帮助确保在使用神经网络之前对输入数据进行了适当的预处理,以提高神经网络的训练效果。
1 | onodes=10 |
这段代码是为了准备目标输出。它创建了一个长度为onodes的零数组(全零数组),然后将第int(all_values[0])个位置设置为0.99。这个位置对应于all_values[0]中的值,通常表示图像中显示的数字。int(all_values[0])的值被用作索引,用于将目标输出数组中对应的位置值设置为0.99。
1 | data_file=open("/home/zuquanzhi/pythonProject/mnist_dataset/mnist_test.csv",'r') |
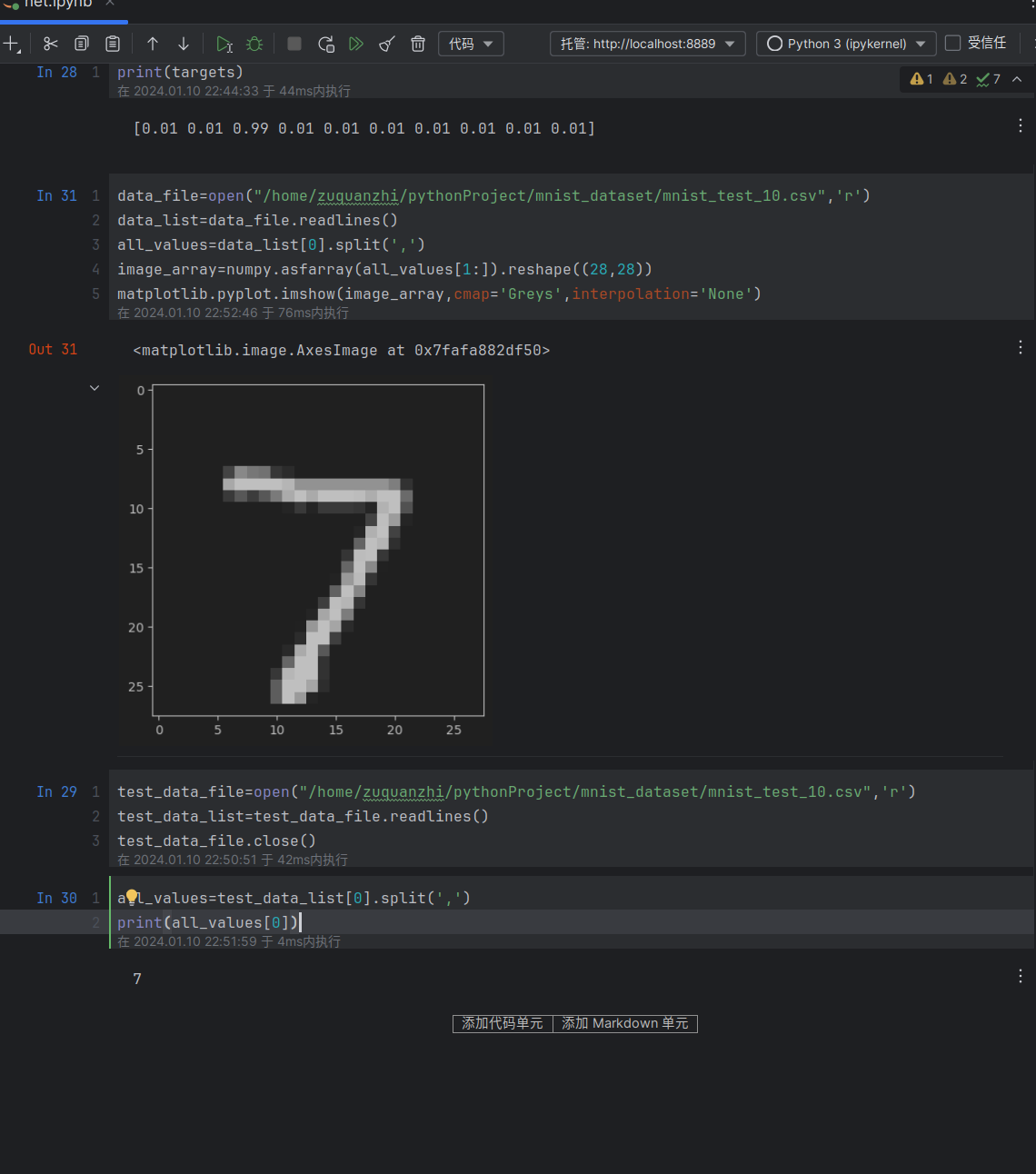
- data_file=open(“/home/zuquanzhi/pythonProject/mnist_dataset/mnist_test.csv”,’r’): 打开了一个名为mnist_test.csv的CSV文件来读取测试数据。
- data_list=data_file.readlines(): 读取CSV文件的内容,并将每一行数据存储在data_list列表中。
- all_values=data_list[0].split(‘,’): 从第一行提取数据,使用逗号作为分隔符将数据拆分为一个值的列表all_values。
- image_array=numpy.asfarray(all_values[1:]).reshape((28,28)): 将all_values列表中的字符串转换为浮点数,并根据这些值创建一个28x28的二维数组 image_array,用于表示图像的像素值。
- matplotlib.pyplot.imshow(image_array,cmap=’Greys’,interpolation=’None’): 使用Matplotlib库中的imshow函数将image_array作为灰度图像显示出来。
- all_values=test_data_list[0].split(‘,’): 这里应该更正为data_list而不是test_data_list,以便使用刚刚加载的测试集数据。这行代码意图是重新读取data_list的第一行数据并将其拆分。
- print(all_values[0]): 打印 all_values 列表的第一个值,这可能是与图像相关联的标签或类别。
