
一文教你学会看多目标检测中的指标
一、先说结论:检测指标到底在衡量什么
目标检测模型要同时回答两个问题:
- 框得准不准(定位)。
- 类别判得对不对(分类)。
所以一套可用的评估体系至少要覆盖两件事:
- 单个预测框是否正确(TP/FP/FN)。
- 模型在不同阈值下的整体表现(PR 曲线、AP、mAP)。
二、核心概念
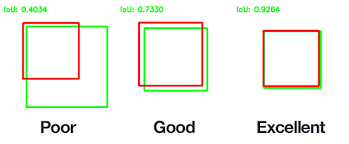
2.1 IoU(Intersection over Union)
IoU 用来衡量预测框和标注框的重叠程度:
一般会设一个阈值(例如 0.5),IoU 达到阈值才有资格被视为“定位正确”。
2.2 TP、FP、FN
在单类别下可以这样理解:
- TP:类别预测正确,且与某个真实框匹配成功(IoU 达阈值)。
- FP:预测了目标,但类别错误或没有匹配到真实框。
- FN:真实目标存在,但模型没有成功预测到。
2.3 Precision 与 Recall
- Precision 高:误检少。
- Recall 高:漏检少。
这两个指标通常互相拉扯,需要结合业务场景取平衡。
三、AP 与 mAP 是怎么来的
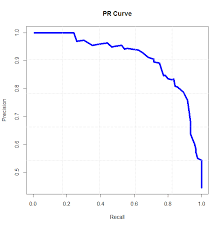
3.1 AP(单类别)
对某个类别:
- 把预测框按置信分数从高到低排序。
- 依次加入预测框,逐步计算 Precision 和 Recall。
- 得到 PR 曲线,曲线下的面积就是 AP。
3.2 mAP(多类别)
对每个类别分别计算 AP,再取平均:
常见报告形式有:
- mAP@0.5:IoU 阈值固定为 0.5。
- mAP@0.5:0.95:在多个 IoU 阈值上平均(更严格)。
四、关于“置信度”的正确理解
很多文章会把置信度写成固定公式,但这里要特别提醒:
- 不同检测器的打分定义并不完全相同。
- 在 YOLO 系列中,常见做法是把 objectness 与分类概率结合用于排序与筛选。
- IoU 主要用于训练中的匹配和评估阶段,不应简单等同为推理时的“置信度组成项”。
实践上,置信度阈值是一个工程参数:
- 阈值高:误检减少,但漏检可能增加。
- 阈值低:召回上升,但误检可能变多。
通常建议结合 PR 曲线和业务容错成本来选阈值,而不是只盯单个数字。
五、怎么读一份检测报告
看到一份结果表,建议按这个顺序看:
- 先看 mAP@0.5:0.95(总体质量基线)。
- 再看各类别 AP(找短板类别)。
- 再看 Precision/Recall(判断是误检问题还是漏检问题)。
- 最后看速度与资源(FPS、显存、延迟)是否满足部署目标。
六、一个可落地的调参思路
如果你的模型“看起来还行,但线上效果一般”,可以按下面排查:
- 先检查标注质量和类别定义是否一致。
- 再检查阈值和 NMS 配置是否合理。
- 最后再做模型结构和训练策略优化。
经验上,数据质量问题经常比模型结构问题更先成为瓶颈。
总结
这篇文章希望解决三件事:
- 理清 IoU、TP/FP/FN、AP、mAP 之间的关系。
- 避免把“置信度”过度简化成单一固定公式。
- 给出一条能直接用于项目排查的读表和调参路径。
如果你后续想看,我可以在下一篇补一个“从混淆矩阵到误检样例回放”的实战流程。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 策悟斋!
